セマンティックセグメンテーションで利用されるloss関数(損失関数)について③
前々回、前回の続きになります。
前々回:
セマンティックセグメンテーションで利用されるloss関数(損失関数)について① - knowwell-livewellの日記
前回:
セマンティックセグメンテーションで利用されるloss関数(損失関数)について② - knowwell-livewellの日記

今回はRegion-based Lossの続きで、Tversky Loss、FocalTversky Lossについて紹介していきたいと思います。
⑤Tversky Loss
Tversky Lossは前回紹介したDice LossおよびIoU Lossの派生形(であり一般化した)損失関数です。Tversky Lossについて紹介するために、Dice Lossのイメージをもう一度考え直してみましょう。

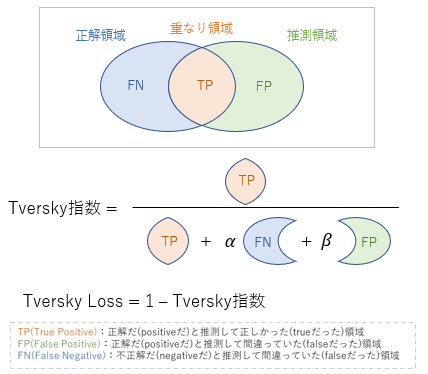
前回の図をTP、FP、FNという3つの領域に分けて書き直すと、Dice係数は上記のような式になります。ここで、注目すべきはDice係数では、FNとFPに等しい値がかけられているということです。「Dice Lossにおいて、FNの領域を強く意識させるようにすることで、小領域のクラス(図中の正解領域)に対してもより推測精度を高めることが出来るのではないか」というのがTversky Lossです。数式と図で表すと以下になります。
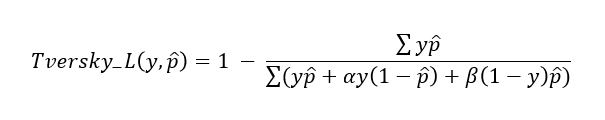
Tversky Lossにおいて、と
を
とするとDice Lossになるのが分かりますね。また、
と
を1とするとIoU Lossになるのが分かりますね。論文中では
を0.7、
を0.3とすると最も精度が良かったようです(すいません、論文と
、
の表記が逆になっていました)。
⑥Focal Tversky Loss
前々回にFocal Lossを紹介しましたが、このFocal Tversky LossはそのアイデアをTversky Lossに適用した損失関数です(名前そのままですが)。Focal Lossは「正解クラスの推測結果が高い簡単なピクセルの全体Lossへの寄与を下げることで、難しいピクセルにフォーカスする」というものでしたが、Focal Tversky Lossは各クラスごとにTversky Lossを計算した後にそれらを加算する際に、Tversky指数が高いクラス(Tversky Lossが低いクラス)の全体Lossへの寄与率を下げようという損失関数です(これまでRegion-based Lossの説明の際に、あるクラスのLossの値を求める式を紹介してきましたが、実際にはクラスごとに計算し、それらを加算する処理をします)。実際の式は以下のようになります。

を変更した際のTversky indexとFocal Tversky Lossの関係は以下のグラフのようになります(元論文*1より引用しています)。

例えば2クラスのセグメンテーションで、片方のクラスのTversky indexが0.6、もう片方のクラスのTversky indexが0.2だった場合を考えます。が1のとき(通常のTversky Loss)、Focal Tversky Lossはそれぞれ0.4と0.8になります。
が3のとき、Focal Tversky Lossは約0.05と約0.5になり、Tversky indexが0.2だったクラスのlossの比重が大きくなっていることが分かりますね。論文中では、
が
の時に最も精度が良かったようです。
続きます...
(間違っていたらコメントでお教えいただけますと助かります。)