セマンティックセグメンテーションで利用されるloss関数(損失関数)について③
前々回、前回の続きになります。
前々回:
セマンティックセグメンテーションで利用されるloss関数(損失関数)について① - knowwell-livewellの日記
前回:
セマンティックセグメンテーションで利用されるloss関数(損失関数)について② - knowwell-livewellの日記

今回はRegion-based Lossの続きで、Tversky Loss、FocalTversky Lossについて紹介していきたいと思います。
⑤Tversky Loss
Tversky Lossは前回紹介したDice LossおよびIoU Lossの派生形(であり一般化した)損失関数です。Tversky Lossについて紹介するために、Dice Lossのイメージをもう一度考え直してみましょう。

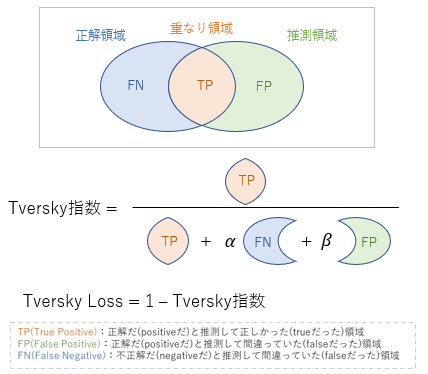
前回の図をTP、FP、FNという3つの領域に分けて書き直すと、Dice係数は上記のような式になります。ここで、注目すべきはDice係数では、FNとFPに等しい値がかけられているということです。「Dice Lossにおいて、FNの領域を強く意識させるようにすることで、小領域のクラス(図中の正解領域)に対してもより推測精度を高めることが出来るのではないか」というのがTversky Lossです。数式と図で表すと以下になります。
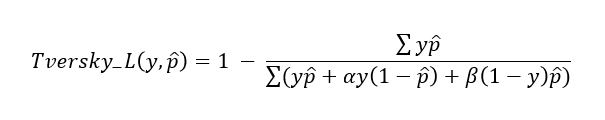
Tversky Lossにおいて、と
を
とするとDice Lossになるのが分かりますね。また、
と
を1とするとIoU Lossになるのが分かりますね。論文中では
を0.7、
を0.3とすると最も精度が良かったようです(すいません、論文と
、
の表記が逆になっていました)。
⑥Focal Tversky Loss
前々回にFocal Lossを紹介しましたが、このFocal Tversky LossはそのアイデアをTversky Lossに適用した損失関数です(名前そのままですが)。Focal Lossは「正解クラスの推測結果が高い簡単なピクセルの全体Lossへの寄与を下げることで、難しいピクセルにフォーカスする」というものでしたが、Focal Tversky Lossは各クラスごとにTversky Lossを計算した後にそれらを加算する際に、Tversky指数が高いクラス(Tversky Lossが低いクラス)の全体Lossへの寄与率を下げようという損失関数です(これまでRegion-based Lossの説明の際に、あるクラスのLossの値を求める式を紹介してきましたが、実際にはクラスごとに計算し、それらを加算する処理をします)。実際の式は以下のようになります。

を変更した際のTversky indexとFocal Tversky Lossの関係は以下のグラフのようになります(元論文*1より引用しています)。

例えば2クラスのセグメンテーションで、片方のクラスのTversky indexが0.6、もう片方のクラスのTversky indexが0.2だった場合を考えます。が1のとき(通常のTversky Loss)、Focal Tversky Lossはそれぞれ0.4と0.8になります。
が3のとき、Focal Tversky Lossは約0.05と約0.5になり、Tversky indexが0.2だったクラスのlossの比重が大きくなっていることが分かりますね。論文中では、
が
の時に最も精度が良かったようです。
続きます...
(間違っていたらコメントでお教えいただけますと助かります。)
セマンティックセグメンテーションで利用されるloss関数(損失関数)について②
前回の続きになります。
前回:
セマンティックセグメンテーションで利用されるloss関数(損失関数)について① - knowwell-livewellの日記
今回はRegion-based Lossにカテゴリー分けされているDice LossとIoU Loss、Tversky Loss、FocalTversky Lossについて紹介していきたいと思います。
③Dice Loss
この損失関数も②Focal Lossと同じく「クラス不均衡なデータに対しても学習がうまく進むように」という意図があります*1。①Cross Entropy Lossが全てのピクセルのLossの値を対等に扱っていたのに対して、②Focal Lossは重み付けを行うことで、(推測確率の高い)簡単なサンプルの全体Loss値への寄与率を下げるよう工夫していましたが、Dice Lossでは正解領域と推測領域の重なり具合(Dice係数)に注目します。領域(の重なり具合)に基づいているという意味でRegion-based Lossにカテゴリー分けされているわけですね。
実際の計算方法は、1 - {2 * (正解と推測の重なり領域) / (正解領域)+(推測領域)}です({}内がDice係数です)。数式で表すと以下になります(図を見るのが分かりやすいですね)。


は正解ラベル、
は推測結果です。例えば、正解ラベルを背景0、前景1のマスク画像とし、推測結果を前景クラスに対するモデル出力(確率)とすると、分母は両者を加算後に全ピクセルで加算を、分子は両者の要素積をとって、全ピクセルで加算すれば前景クラスに対するDice Lossを求めることが出来ます。ただし、計算上の安定性のために(分母が0にならないように)、分母と分子に1を足して計算するのが一般的です。論文によっては分母の
と
を2乗しているものも見られました。また、いくつかの実装を見ると、出現回数の少ないクラスのDice Lossのみを計算しているものや、(正解マスクをone-hot表現に変換し)各クラスのDice Lossの(重み付け)平均をとっているものなど多少バリエーションがあるように思います(Pytorchの公式実装が欲しいですね)。
④ IoU(Jaccard) Loss
IoU Lossも③Dice Lossと同じく領域の重なり具合に注目します。IoUと言えば、セマンティックセグメンテーションの精度を測る指標としておなじみですよね。(個人的なイメージですが)評価指標としてはDiceよりもIoUを使うことが多く、Loss関数はIoUよりもDiceを使うことが多い気がします。医療セグメンテーション分野では評価指標としてDice係数(DSC)がよく使われているようですね。
IoU Lossの計算方法は、1 - {(正解と推測の重なり領域) / (正解領域)+(推測領域)- (正解と推測の重なり領域)}です(「かつ」/「または」ですね)。数式で表すと以下になります(こちらも図を見るのが分かりやすいですね)。

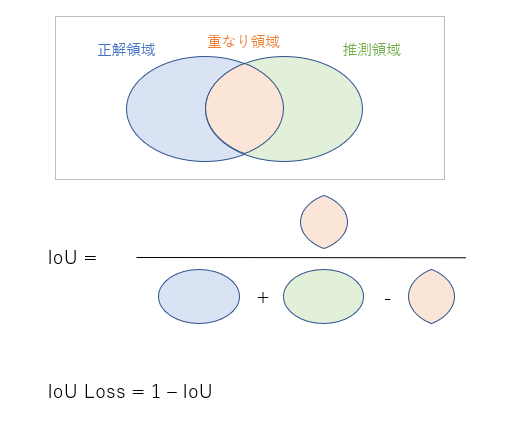
IoU Lossに関しては、Dice Lossと同じ要領で理解できるかなと思います。
ところで、IoUとDiceにどのような違いがあるのでしょうか。Dice Lossの図(式)における分子の2倍を分母の倍と考えると、Diceは正解領域と推測領域の平均に対する重なり領域の割合を計算していると考えられますが、IoUは正解領域と推測領域の「または」領域に対する割合を計算していますね。ということは、例えば推測領域が広がっている場合には、DiceよりもIoUの方が(分母が大きくなるため)値が小さくなりそうです。
Deep Learning等の精度評価において、F値(Dice)とIoU(Jaccard)のどちらを選択するべきか? - OPTiM TECH BLOG
こちらのブログは実際にDiceとIoUの違いを分かりやすく説明されています。IoUの方が厳密に評価できるという意味で評価指標として広く活用されているのかもしれないですね(ただ、そうなるとLossもIoUの方が良い気がするのですが)。
続きます..
(間違っていたらコメントでお教えいただけますと助かります。)
セマンティックセグメンテーションで利用されるloss関数(損失関数)について①
今回はセマンティックセグメンテーション(領域推定)のタスクでよく利用されるloss関数をまとめます(あまり利用されていないものも含めます)。
1. セマンティックセグメンテーションとは?
セマンティックセグメンテーションは画像中の対象物体の領域を推定するタスクで、畳み込みニューラルネットワーク(CNN)を活用することで精度良く推定できるようになったタスクの一つです。
このタスクにおける代表的なCNNモデルは、FCN、SegNet、U-Net、PSPNet、DeepLab familyなどがあります。一般的なセマンティックセグメンテーションタスクにおいて、現状のデファクトスタンダード(まずはこれ試そうモデル)は?と言われれば、2018年に発表されたモデルですが、DeepLab V3+なんじゃないかなと思っています(あくまで個人的な考えです)。
このCNNを学習させるためには、モデル出力と正解画像との差(誤差)を計算する必要があるのですが、ここで登場するのがloss関数です。個人的によく思うのですが、このloss関数の選択はどのくらい収束速度、精度に影響を及ぼすのでしょうか?(このブログでは実際に評価までしませんが..)

2. セマンティックセグメンテーションで利用されるloss関数

セマンティックセグメンテーションのloss関数に特化したサーベイ論文として、2020年の「A survey of loss functions for semantic segmentation*1」があります。ほかにも、セグメンテーションのloss関数をリストしているgithubのページ*2もあります。これらを参考にしながら、以降ではCross Entropy Loss、Focal Loss、Dice Loss、Tversky Loss、Boundary Loss、HD Lossについて紹介していきます(本記事はCross Entropy LossとFocal Loss)。
①Cross Entropy Loss
クラス分類でお馴染みのLoss関数です。セマンティックセグメンテーションもピクセル単位でクラス分類するタスクですので、こちらのLoss関数は一般的によく使用されていると思います。Cross Entropy Lossは2つの確率分布(教師データの分布とモデル出力の分布)の差を表しているので、図中においてDistribution-based Lossにカテゴリー分けされています。数式は以下になります。

p(x)が正解ラベル、q(x)が推測結果です。これは正解ラベルをone-hotベクトルとすると、正解ラベルが1の推測結果(確率)の対数の負を計算すればよいということになります。もっと言うと、正解クラスの推測結果(確率)の対数の負を計算すればよいということですね。(「正解ラベルが1の推測結果だけ計算すればよい」と考えてしまうと、「セマンティックセグメンテーションの正解画像の1の値の領域だけ計算すればいいのか」みたいな間違った考えをしてしまいかねないので気を付けましょう。)ちなみにPytorchのtorch.nn.CrossEntropyLossはTargetとしてone-hotベクトルではなく、正解クラスのインデックスを与えるので、注意が必要です。そのため、one-hot表現で正解ラベルが(0,0,1)の場合は2を入れないといけません。これは結構ややこしいポイントだと思います。以下の記事がtorch.nn.CrossEntropyLossの使い方として(公式リファレンスと併せて見ると)分かりやすいと思います。([PyTorch]CrossEntropyLossを数式入りでちょっと理解する - Qiita)
話がかなり逸れてしまいました。とにかくセマンティックセグメンテーションにおけるCross Entropy Lossをまとめると、以下の図のようになります。

②Focal Loss
「不均衡データに対しても学習がうまくいくように」という意図で設計されたLoss関数です。セマンティックセグメンテーションにおける不均衡データとは、例えば、画像に占める対象物体の面積がとても小さいようなデータです。実際には、Cross Entropyへの重み付けにより、正解クラスの推測結果(確率)が高い、簡単なピクセルのLossへの寄与を小さくすることで、推測結果(確率)が低い、難しいピクセルにフォーカスするようにします。図中ではCross Entropyから「Down-weight easy examples」となっていますよね。数式は以下になります。

ここで、は正解クラスの推測結果(確率)です。
のおかげで、推測結果(確率)が大きい場合はその値が小さくなることが分かります。ちなみに、
が0の場合は通常のCross Entropy Lossになります。提案論文中では
と設定しているようです。以下のサイトにPytorch実装があります。
https://github.com/JunMa11/SegLoss/blob/master/losses_pytorch/focal_loss.py
続きます...
(間違っていたらコメントでお教えいただけますと助かります。)
Python/OpenCVで輪郭検出と輪郭内領域の塗りつぶし
今回はPythonとOpenCVを使って、「輪郭検出」と「検出した輪郭内の塗りつぶし」処理を行ってみたいと思います(画像は著作権フリーのものを使用しています)。
https://pixabay.com/ja/vectors/%e3%83%91%e3%82%bf%e3%83%bc%e3%83%b3-%e8%91%89%e3%81%ae%e3%83%91%e3%82%bf%e3%83%bc%e3%83%b3-%e7%be%8e%e8%a1%93-6854140/

まずは以下のライブラリをインポートします。
import numpy as np import cv2 import matplotlib.pyplot as plt from copy import deepcopy import statistics
続いて、画像を読み込みます。
img_BGR = cv2.imread("image.png")
img = cv2.cvtColor(img_BGR, cv2.COLOR_BGR2RGB)

輪郭を検出するためには、対象領域を表すマスク画像(2値画像)が必要になります。今回の画像は背景色が一様なので、その値かどうかでマスク画像を作成できます。まず、背景色を求めるために最頻値を算出してみます(RGBセットで最頻値を算出したいのですが、良い方法が見当たらなかったので、RGBそれぞれで計算してから確認する方法をとっています)。
#最頻値を調べる R_mode = statistics.mode(img[:,:,0].flatten()) print(R_mode) G_mode = statistics.mode(img[:,:,1].flatten()) print(G_mode) B_mode = statistics.mode(img[:,:,2].flatten()) print(B_mode) #実際の画素値を見て確認してみる print(img[0,0,:]) print(img[10,10,:])
これで背景色が(244,242,228)であることが分かりました。続いて、対象画像と同じサイズの配列(チャネル1、要素0)を用意し、最頻値でない箇所は255に変換します。
mask = np.zeros((img.shape[0], img.shape[1])) mask[(img[:,:,0] != R_mode) & (img[:,:,1] != G_mode) & (img[:,:,2] != B_mode)] = 255

このマスク画像を用いて、輪郭を検出します。
# 輪郭の検出 contours, hierarchy = cv2.findContours(mask.astype("uint8"), cv2.RETR_LIST, cv2.CHAIN_APPROX_SIMPLE)
検出した輪郭を対象画像上に描画し保存してみます。ただし、小さい領域の輪郭に関しては今回除いています(面積で判定)。
for i in range(len(contours)): if cv2.contourArea(contours[i]) > (img.shape[0] * img.shape[1]) * 0.005: img_with_line = deepcopy(img_BGR) img_with_line = cv2.drawContours(img_with_line, contours, i, (0,255,0), 2) cv2.imwrite("result" + str(i) + "_line.png", img_with_line)

ちなみに、以下のようにすれば1つの画像上に検出した輪郭すべてを描画できます。
img_with_line = deepcopy(img_BGR) for i in range(len(contours)): if cv2.contourArea(contours[i]) > (img.shape[0] * img.shape[1]) * 0.005: img_with_line = cv2.drawContours(img_with_line, contours, i, (0,255,0), 2) cv2.imwrite('allresult_line.png', img_with_line)

続いて、塗りつぶしには「cv2.fillPoly」を利用します。
for i in range(len(contours)): if cv2.contourArea(contours[i]) > (img.shape[0] * img.shape[1]) * 0.005: img_with_area = deepcopy(img_BGR) img_with_area = cv2.fillPoly(img_with_area, [contours[i][:,0,:]], (0,255,0), lineType=cv2.LINE_8, shift=0) cv2.imwrite("result" + str(i) + "_area.png", img_with_area)

先ほどと同じように、以下のようにすれば1つの画像上にすべてを描画できます。
img_with_area = deepcopy(img_BGR) for i in range(len(contours)): if cv2.contourArea(contours[i]) > (img.shape[0] * img.shape[1]) * 0.005: img_with_area = cv2.fillPoly(img_with_area, [contours[i][:,0,:]], (0,255,0), lineType=cv2.LINE_8, shift=0) cv2.imwrite("allresult_area.png", img_with_area)

これで完成です。
おまけ
ちなみに、今回の画像は背景色が一様なので、背景色で塗りつぶすようにすればその模様を消すことが可能です。
for i in range(len(contours)): if cv2.contourArea(contours[i]) > (img.shape[0] * img.shape[1]) * 0.005: img_with_area = deepcopy(img_BGR) img_with_area = cv2.fillPoly(img_with_area, [contours[i][:,0,:]], (int(B_mode),int(G_mode),int(R_mode)), lineType=cv2.LINE_8, shift=0) cv2.imwrite("result" + str(i) + "_area_remove.png", img_with_area)

Python/OpenCVで画像中の特定色領域を抽出する
今回はPythonとOpenCVを使って、ちょっと遊んでみようと思います。
実際にやることは下図のように「特定の色がついた領域を抽出する」です。
(対象画像は本ブログのアイコンで、エルモとクッキーモンスターの領域をいい感じに2値化するイメージです。)

まずは以下のライブラリをインポートします。
import numpy as np import cv2 import matplotlib.pyplot as plt from copy import deepcopy
続いて、画像を読み込みます。
img = cv2.imread("image.jpg")
plt.imshow(img)

OpenCVはBGRで画像を読み込むので、そのままmatplolibでimshowするとBチャネルとRチャネルの値が入れ替わった画像が表示されてしまいます(これあるあるだと思うのですが私だけでしょうか)。ただ、コードを書く上では処理対象のチャネルを間違えさえしなければよいので、表示を気にしすぎる必要はないかなとも思います。
一応、下のコードのようにRGBに変換しておきましょう。
img_BGR = cv2.imread("image.jpg")
img = cv2.cvtColor(img_BGR, cv2.COLOR_BGR2RGB)
plt.imshow(img)

画像のRGBチャネルをそれぞれ見てみましょう。
#R channelの可視化 plt.imshow(img[:,:,0], cmap="gray") plt.show() #G channelの可視化 plt.imshow(img[:,:,1], cmap="gray") plt.show() #B channelの可視化 plt.imshow(img[:,:,2], cmap="gray") plt.show()



当たり前ではありますが、Rチャネル(一番上)にエルモの領域が強く出ていて(白色に近い)、Bチャネル(一番下)にクッキーモンスターの領域が強く出ています(白色に近い)。そこで、RチャネルとBチャネルに注目し、閾値処理してみましょう(今回は閾値を0.7に設定しました)。
"""Rチャネルの値を閾値処理""" #0~1に正規化 R_channel = img[:,:,0] / np.amax(img[:,:,0]) #コピーしておく ROI_R = deepcopy(R_channel) #閾値処理 ROI_R[R_channel < 0.7] = 0 ROI_R[R_channel >= 0.7] = 1 #表示する plt.imshow(ROI_R,cmap="gray")

"""Bチャネルの値を閾値処理""" #0~1に正規化 B_channel = img[:,:,2] / np.amax(img[:,:,2]) #コピーしておく ROI_B = deepcopy(B_channel) #閾値処理 ROI_B[B_channel < 0.7] = 0 ROI_B[B_channel >= 0.7] = 1 #表示する plt.imshow(ROI_B,cmap="gray")

白色はRGBチャネルすべてに大きい値が出るので、目の部分も抽出されています。ちなみに0~1に正規化する意味は特にないです。では、それぞれの領域を統合しましょう。
#Rチャネルで抽出した領域とBチャネルで抽出した領域を結合する ROI_RB = np.maximum(ROI_R, ROI_B) #表示する plt.imshow(ROI_RB,cmap="gray")

これでいいのですが、ちょっと後ろの線が気になるので、モルフォロジー変換(オープニング)で消してしまいます。カーネルサイズは画像サイズに応じて変更する必要があります。
#オープニング処理する kernel = np.ones((15,15),np.uint8) opening = cv2.morphologyEx(ROI_RB, cv2.MORPH_OPEN, kernel) #表示する plt.imshow(opening,cmap="gray")

ちなみにOpenCVで保存するときは、0~255でuint8にしておかなければいけません。
opening = opening * 255. cv2.imwrite("result.jpg", opening.astype("uint8"))
これで完成です。
終わりに
この記事は元々違うやり方(もっと面白い処理方法)を紹介しようと思って書き始めたのですが、諸々の事情でやめることになり、こんな感じになりました。Lab空間やHSV空間に変換して抽出してみるのも面白いと思います。
「24 Hours With Chloë Grace Moretz」の英語を眺める③
前々回、前回に引き続き、3回目(最終回)になります。
前々回 : 「24 Hours With Chloë Grace Moretz」の英語を眺める① - knowwell-livewellの日記 (hatenablog.com)
前回 : 「24 Hours With Chloë Grace Moretz」の英語を眺める② - knowwell-livewellの日記 (hatenablog.com)
5. 8:00 PM @ Brothers Sushi, Woodland Hills
So we are about to go into Brothers Sushi with my friend Mark, who is the head chef and owner of this place, and yeah, eat the best sushi in Los Angeles, in my opinion, which is a pretty, it's a pretty high bar.
(雑訳)これから「Brothers Sushi」へ行くの、料理長でオーナーのMarkとは友達なのよ。ロスで一番の寿司だと思っているわ。
(They are) one of the first places I went when I was 12 or maybe 13 years old for kick ass press was to Japan, to Tokyo. And I had such a fun time eating so much sushi and being a part of that and learning more about it and traditions behind it. When I came back to LA, I always love to find little sushi holes in places that are kind of special and singular. And I met Mark at Austin Avo and then we would just have conversations and talk about food and life. And we became friends.
(雑訳)12歳か13歳のころ「キックアス」の宣伝で初めて行った場所の一つが確か日本の東京だったわ。たくさんの寿司を食べたり、その背景にある伝統について学んだりと、とても楽しい時間を過ごしたわ。ロスに帰ってきたときに、お寿司が食べられる場所をいつも好んで探していたわ。MarkとはAustin Avo(?)で会って、食や人生について話し合って、友達になったの。
(Mark) You ordered "omakase" , let me trust me and make some stuff. So I like to use a ceder pine.
(Chloë) This is kinnme dai right?
(Mark) Kinnme dai yes. You can graze some yuzu.
(Chloë) Oh. Like that. And then brush?
(Mark) Yeah, brush. There you go. Nice touch.
(雑訳)
Mark:よく「おまかせ」を注文するよね。僕は針葉樹材のまな板を使うの好きだよ。
Chloë:これは金目鯛?
Mark:そうそう、ゆずを乗せるからちょっとつまむことができるよ。
Chloë:ブラッシングでかけるの?
Mark:そう、はいどうぞ。
(Chloë) Wow that is so good.
(Mark) The Santa Barbara abalone Santa Barbara urchin, your favorite.
(雑訳)
Chloë:これとてもおいしいわ。
Mark:サンタバーバラ産のアワビとウニだね、君のお気に入りの。
I enjoy within roles. Being able to scare myself a little bit. Trying to figure out, you know, did I bite off more than chew? Can I actually achieve this role? You know, am I the best person for this role? And then proving it to yourself, you know, against all odds and working your way through those emotions on your own and working through your own psyche, you know, in your own mind telling you maybe that you can't do it. I'm trying not to make decisions, you know, months in advance even just trying and, and, take it day by day. And that way, what projects come may come and um meet them where I am that day. You know.
(雑訳)私は役を演じるのを楽しんでいて、少し自分にプレッシャーをかけることができるわ。できないことをやろうとしていないか?この役を演じ切ることができるのか?この役に自分が一番適しているのか?っていう疑問(精神状態)に対して、困難にもかかわらず証明するの。
(メモ)「I'm trying not to make decisions, you know, months in advance even just trying and, and, take it day by day. And that way, what projects come may come and um meet them where I am that day. You know. 」の部分は「何か月も前から決断したりせず、時間をかけて判断するようにしているの。そうして、そのときの自分で次のプロジェクトに取り組むようにしているのよ。」みたいな感じでしょうか。ちょっと分かりにくいですね。
(Mark) So this is a nodoguro, Japanese sea perch, my favorite white fish with a Japanese citrus paste on top.
(Chloë) That is so good. Cheers.
(雑訳)
Mark:これはノドグロで僕のお気に入り、ゆずのペーストをのせているよ。
Chloë:とてもおいしいわ。
完.
「24 Hours With Chloë Grace Moretz」の英語を眺める②
前回(「24 Hours With Chloë Grace Moretz」の英語を眺める① - knowwell-livewellの日記 (hatenablog.com))の続きになります。
4. 4:00 PM @ Boxing Studio, Hollywood
(Trainer) The biggest things is about protecting your knuckles and your wrists, and then making sure it's like solid. (Exactly. Let it go.)
(Chloë) I don't go breaking my own bones, just breaking your bones.
(Trainer) Just breaking whatever you need to. (Make a fist.)
(雑訳)
トレーナー:最も大事なことは指の関節と手首を守ること、バンテージ(テーピング)がしっかり固定されているか確かめること。
クロエ:私の骨が折れることはないから、あなたの骨を折るだけね。
トレーナー:折りたいものならなんでも。
I really started training my body at a young age, especially when I did kick ass. It kinda of opened me up to the world of movement. And one thing I found really empowering was, you know, fight training and boxing and kickboxing. And it allowed me to find not just, you know, strength and rhythm, but also allow me to find kind of a gravity within myself, no matter how crazy my world gets or my day gets, or you know, my hour gets, it's an amount of time that I can kind of take to myself and feel what it feels like to, to connect with my body and my soul and get my center. I think at a young age, I kind of realized exactly what I wanted to stand for and who I wanted to stand for and not just speak for myself, but to, you know, use my platform as a microphone and a spotlight for those that might not have the ability or the opportunity to have that.
(雑訳)「キックアス」をやっていたときに自分の体を鍛え始めたんだけど、それで運動の世界に足を踏み入れることになったの。自分に活力を与えたスポーツは、格闘トレーニング、ボクシングやキックボクシングだったわ。それらを通して、強さやリズムだけでなく、自分の中の重力(のようなもの)を発見することができたの。スポーツをしている時間は自分自身のために使っている時間で、体と心がリンクして自分の中心になっていくのを感じることが出来るわ。小さいころに何を表現(支持)したいかやどんな人を表現(支持)したいかを理解して、自分のことだけを話すのではなく、発信する能力、機会がない人々のためにマイクやスポットライトを利用したいと思っているわ。
When I turned 18, I realized a lot about myself that I hadn't worked through and I jumped into therapy twice a week and I stopped acting for a year. And I got back into working out. I stopped training for like two years before that. And I think I really lost my, my balance. You know, my footing when I came out, the other side of that, you know, about 20 years old, I felt that I not only was able to speak my truth, but I was able to stand up for what I really believe in on a daily basis.
(雑訳)18歳になったころ、(今まで対処したことがなかったような感情(感覚)を味わって、)今まで知らなかった自分自身について多くのことを悟って、1週間に2回のセラピーを受けながら、女優業を1年間休止したの。それ以前まで2年間近くトレーニングしていなかったんだけど、また体を鍛えるようになったの。そのころは自分のなかのバランスを失っていたように思う。20歳くらいのころには、自分のことを正直に話せるようになっただけでなく、日ごろから自分が信じることを支持することができるようになったように感じたの。
Over the last year, I've gone through a lot, being in Mother/Android was something that I needed that outlet I craved to be back on set. I craved to be back into a character shoes, or director and writer. Mattson Tomlin wrote this about his family, you know, and his parents who went through the Romanian Revolution in the eighties. And he was given up for adoption. This baby belly that I wore was 21 pounds.I had never experienced that before. And then, you know, doing these scenes and I would just look over at Matt and see him there. And you know, he's a standing representation of this whole thing. And it was one of the most incredible experiences in my career. Like it changed me as a person in lots of ways.
(雑訳)この1年間、妊婦役を演じることで多くのことを経験したし、この役を演じるために早くセットに戻りたいと強く思ったの。脚本家のMattson Tomlinは彼の家族のことについて書いていて、彼の両親は80年代にルーマニア革命を経験して、彼は養子に出されたの。妊婦に見えるように着たシリコンのお腹は21ポンド(約10kg)で、こんな経験したことなかったわ。シーンを撮影している中、Mattを見るの、だって彼はこの物語の象徴だから。自分のキャリアの中でとても素晴らしい経験の一つだったわ。人として成長させてくれたと思うの。
(メモ)海外huluオリジナル映画「Mother/Android」の撮影について。日本ではNetflixで視聴可能です。ちなみに、huluは日本では日テレ傘下で海外ではディズニー傘下。
続く...